

Case Study

This case study summarizes a multi-phase project the Institute completed for a customer service-oriented division at a state agency. The project focused on business intelligence analysis and process documentation.
Before the project began, customers were experiencing long wait times. And the burden on employees coping with the overwhelming customer volume was made even more challenging because of unclear and undocumented processes.
After implementation of the recommendations we made, and other internal changes, customer wait times decreased nearly 60% from a median of 52 minutes to 21 minutes. The online process documentation we developed received 3,000 hits per day from division staff.
The agency had years of transactional data that had been developed and used for purposes other than gaining insights into division operations and how these operations could be improved. In fact, analysts at the agency had never had access to the data before our project. After this project, this data became a critical resource to inform and enhance decision-making.
Initially, there were major data quality issues because the transactions could not be associated with the office where they took place. They were only associated with the laptops used to complete them, and the laptops were taken to different offices throughout the week. Moreover, some office addresses were unverified. We began the project by verifying all office addresses and developing a script to assign each transaction to the correct location based on time of day and day of week.
We were able to summarize a billion records in ways the agency had never seen before. For example, we were able to identify peak transaction days of the week, hours of the day, and months of the year.
Based on these summary statistics and working with the agency, we identified two key areas in need of improvement:
- Resource allocation
- Process consistency
Resource Allocation
The agency had two critical resources to allocate across the state:
- Employees
- Offices
Employees
Allocating staff had two dimensions: time and place. This meant that we were looking at not only where the employees would be allocated, but also when. Scheduling was prioritized to identify staff deficits and surpluses.
Many office managers suspected they needed more employees in the afternoon because that was when the offices were most crowded. In fact, our analysis revealed the afternoon crowds were caused by falling behind first thing in the morning. Counterintuitively, increasing employees in the morning before the office was packed would improve customer service throughout the day.
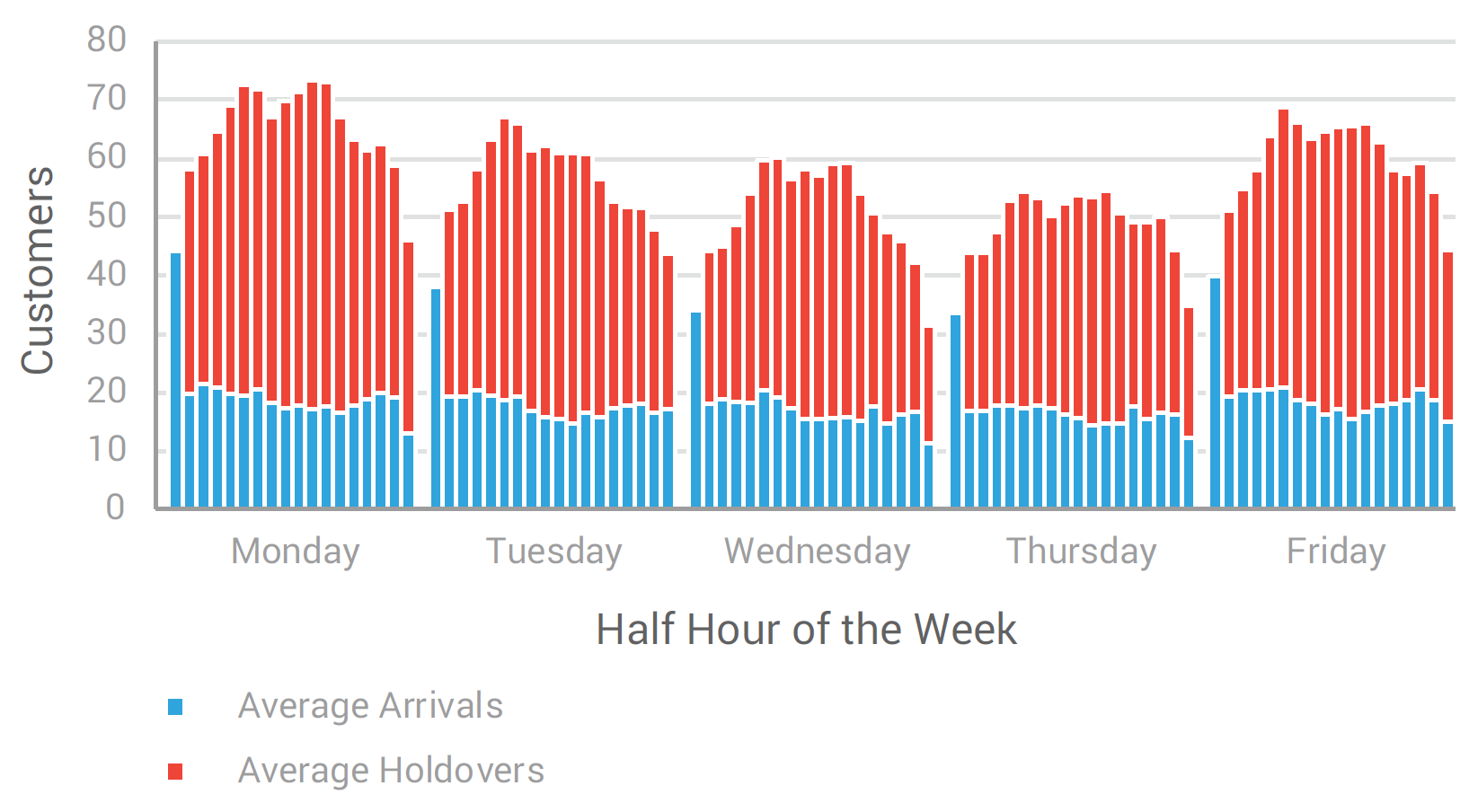
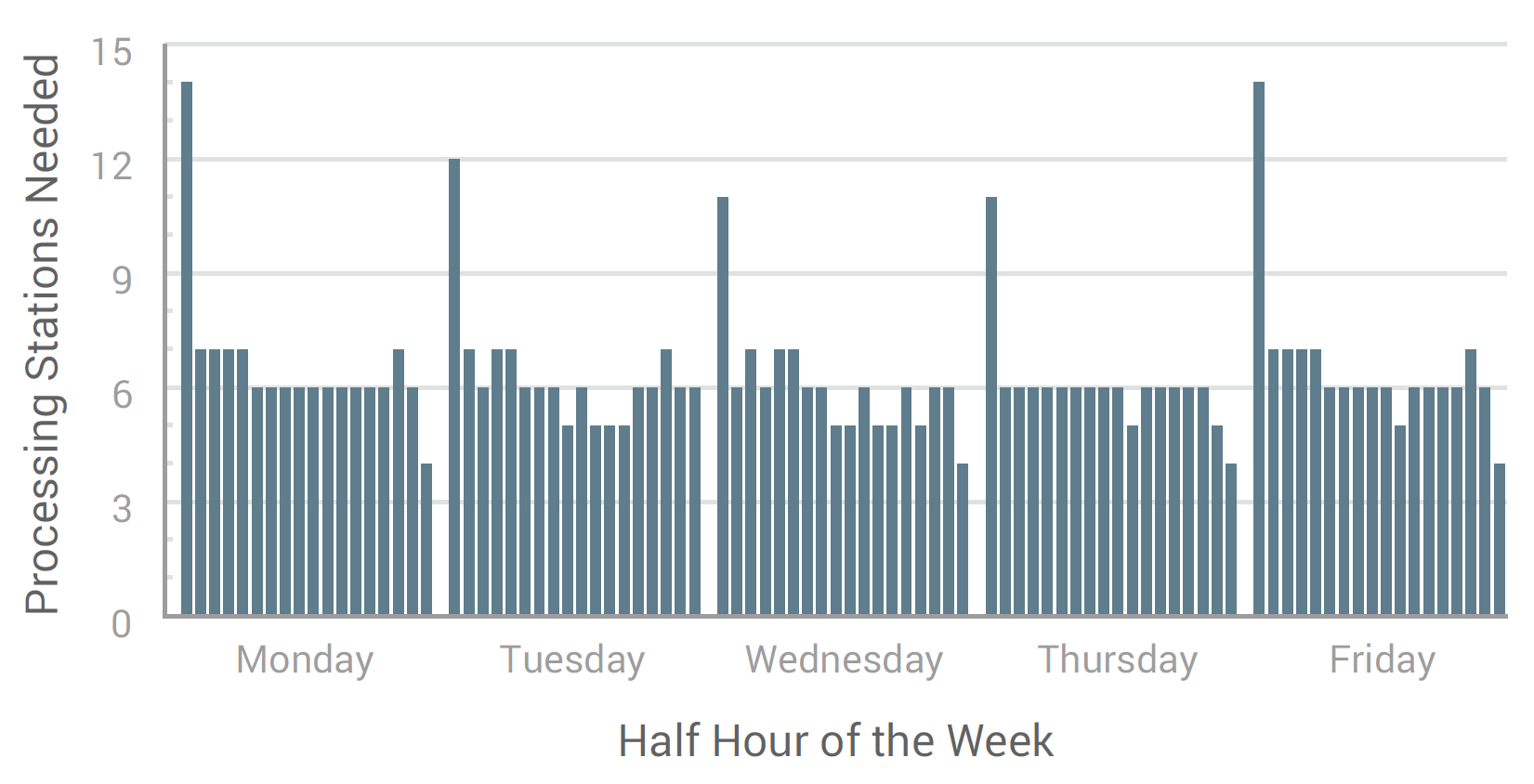
We were able to determine the ideal employee schedule for each office across the state using queuing theory. We then used the employee schedules to identify the minimum number of employees required at an office to ensure coverage throughout the day. If the office did not have enough employees to meet the schedule requirements, they were considered to have a negative employee gap. If they had more than enough, the office was considered to have a positive employee gap.
Using the employee gap analysis, we were able to identify where more staff was necessary office-by-office. In areas where existing office capacities had been reached, ideal new locations were identified.
Title
Offices
We were able to identify ideal office locations using the k-means clustering algorithm. Further, we were able to correlate nearby population to an estimated number of employees necessary at each location to serve likley customers.
A clustering algorithm’s goal is to create groups which minimize the within-group variation and maximize the between-group variation. In other words, to create offices that are close to their customers and far from other offices. The k-means clustering algorithm follows 5 steps:

- Enter a number (k) of offices (means).
- Create (k) random office points in a specified area.
- Assign customers to the nearest office.
- Optimize office locations by placing them in the customer center of density.
- Repeat steps 2 – 4 until customer assignments do not change during step 3.

Before running the model, existing offices were used in the algorithm as constant means. In other words, during step 4 of the process, the existing offices would not move. Additionally, the customers we used were population points, but we weighted those points based on employee gaps where customers near offices with negative employee gaps were preferred by the model. Without this weighting, we might come to the wrong conclusion.
Instead, we see the model respond to these gaps and identify a reasonable ideal office location. Finally, a list of nearby ZIP codes was provided to the agency so that their staff could identify available properties.
Process Consistency

The agency’s resource allocation issues were further complicated by outdated and complex policy and procedure manuals.
Policy and procedure documentation were printed and distributed in large binders and then maintained via a system of email memos and through employee tenure and experience. Formal manual updates were cumbersome and time consuming, and therefore, infrequent. This ad hoc policy documentation approach led to process inconsistency across the State and contributed to longer transaction and customer wait times. Moreover, when the most tenured employee at an office retired, it posed a significant risk to basic operations.

To solve this problem, we developed an internal single-source online documentation system that enabled publishing to multiple formats with the click of a button.
By creating a single-source, formalized processes and procedures led to standardized training and reference materials increasing policy consistency while helping reduce transaction times across the State.
Additionally, because policy tends to change with new leadership and with legislative sessions, updating policies became more streamlined by having only one source of information rather than training, email, and other official communications.
The online structure also enabled employees to refresh their knowledge of an entire process or search for quick answers. After developing the initial online version, the Institute trained agency staff to assume responsibilities and keep the online document up to date.
The project was award winning but more importantly, frontline employees and supervisors were more comfortable following agency policy and law knowing it would be consistently implemented at every office.